Overview
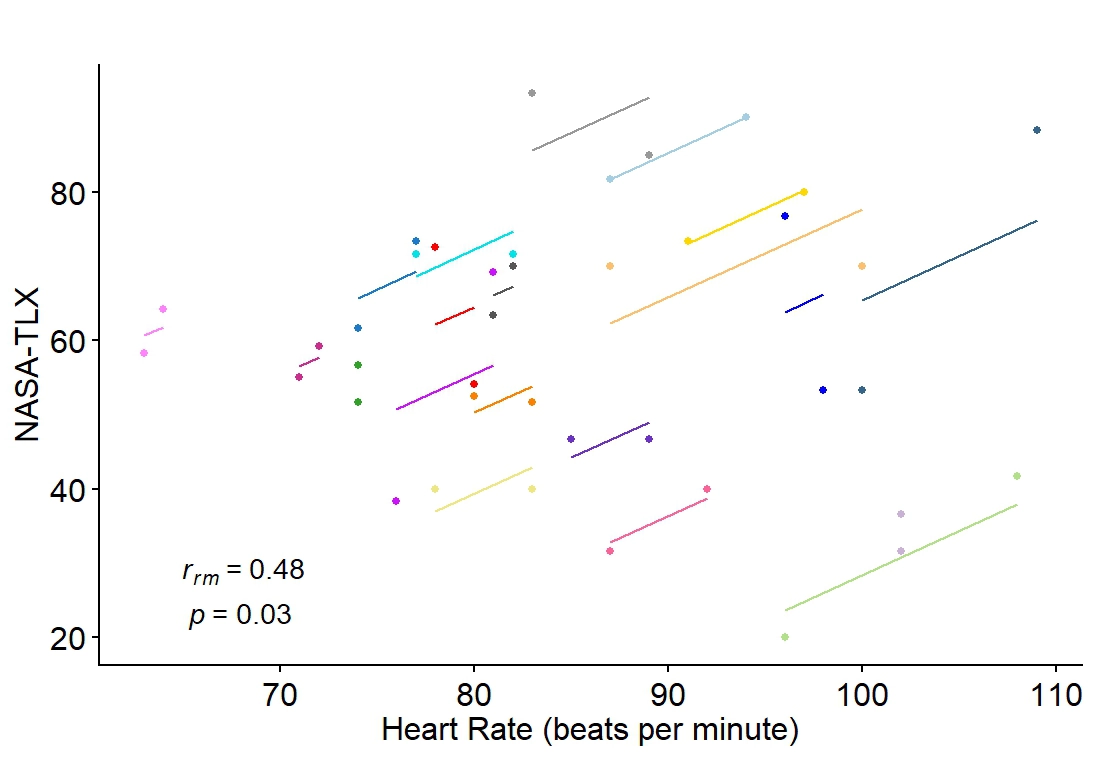
Can your smartwatch tell when you're burned out? I tackled this question during 2025 UC Love Data Week, an event focused on discovering, managing, and sharing data. Using R, I examined potential correlations between physiological metrics and mental workload among 20 subjects. I found a significant relationship between heart rate and NASA-TLX scores. Thanks to affordable wearable tech making massive amounts of real-time biological data available to everyone, my work can be used to improve workplace health and safety in the digital age.
Introduction
Mental workload (MWL) characterises an individual’s level of cognitive engagement and effort while performing tasks. As task demand increases, human performance declines. Research shows higher MWL causes increased fatigue, injury, errors and accidents. Mental workload plays a crucial role across different industries, especially in labor-intensive and safety-critical spaces.
Repeated measures correlation (rmcorr) has several advantages over other techniques: it can handle repeated measures data without averaging it. It's helpful for studying how a variable changes within a person over time. By calculating the rmcorr coefficient (rrm), we can examine how an individual’s physiology shifts with their mental effort, providing a high-resolution map of human performance under pressure.
The Dataset
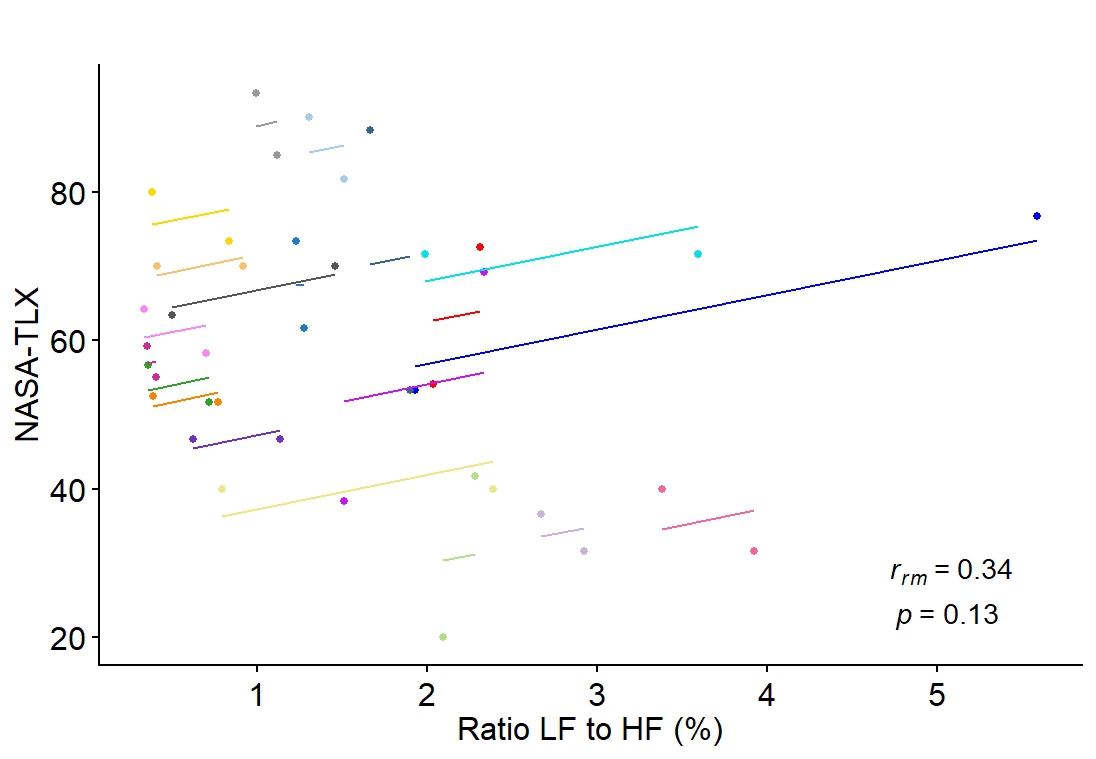
The dataset is from an experiment (Izzah et al., 2022) exploring machine learning models. 30 subjects completed two cognitive tests (d2 Attention Test and Switcher Featuring Task) during which their Heart Rate Variability (HRV) was monitored as a physiological indicator of mental workload. This analysis uses unpublished NASA Task Load Index (TLX) scores, a self-reported measure of perceived mental workload. Higher scores reflect higher engagement of mental workload in each task.
Hypotheses
Does heart rate significantly correlate with TLX scores across the two cognitive workload tests? Does the low-frequency to high-frequency ratio significantly correlate with TLX scores across these tests? These questions are posed in the form of two null hypotheses:
- H01= There is no significant correlation between heart rate and NASA-TLX scores across the two cognitive workload tests
- H02= There is no significant correlation between the ratio LF to HF and NASA-TLX scores across the two cognitive workload tests